Forward vs Reverse KL Divergence: Why the Direction Matters
Why the direction of your KL divergence matters more than you think...

AI Researcher @ AWS
I'm an AI researcher at Amazon Web Services (AWS), working on agentic AI and large language models. I work on post-training — RLHF, reward modeling — and figuring out how to evaluate LLMs in ways that actually reflect real-world usefulness. I also work on LLM environments: how to design diverse, realistic environments that let agents learn and improve through richer interactions.
Previously, I completed my PhD at USC on training efficiency in deep learning, and worked on synthetic data for NLP tasks like named entity recognition and relation extraction.
arXiv:2510.17052
Read PaperarXiv:2510.17058
Read PaperNAACL 2024 Findings
Read PaperAsilomar Conference 2022
Read PaperIEEE ISIT 2019
Read PaperCWIT 2019
Read PaperIEEE Photonics Journal
Read PaperCWIT 2017
Read Paper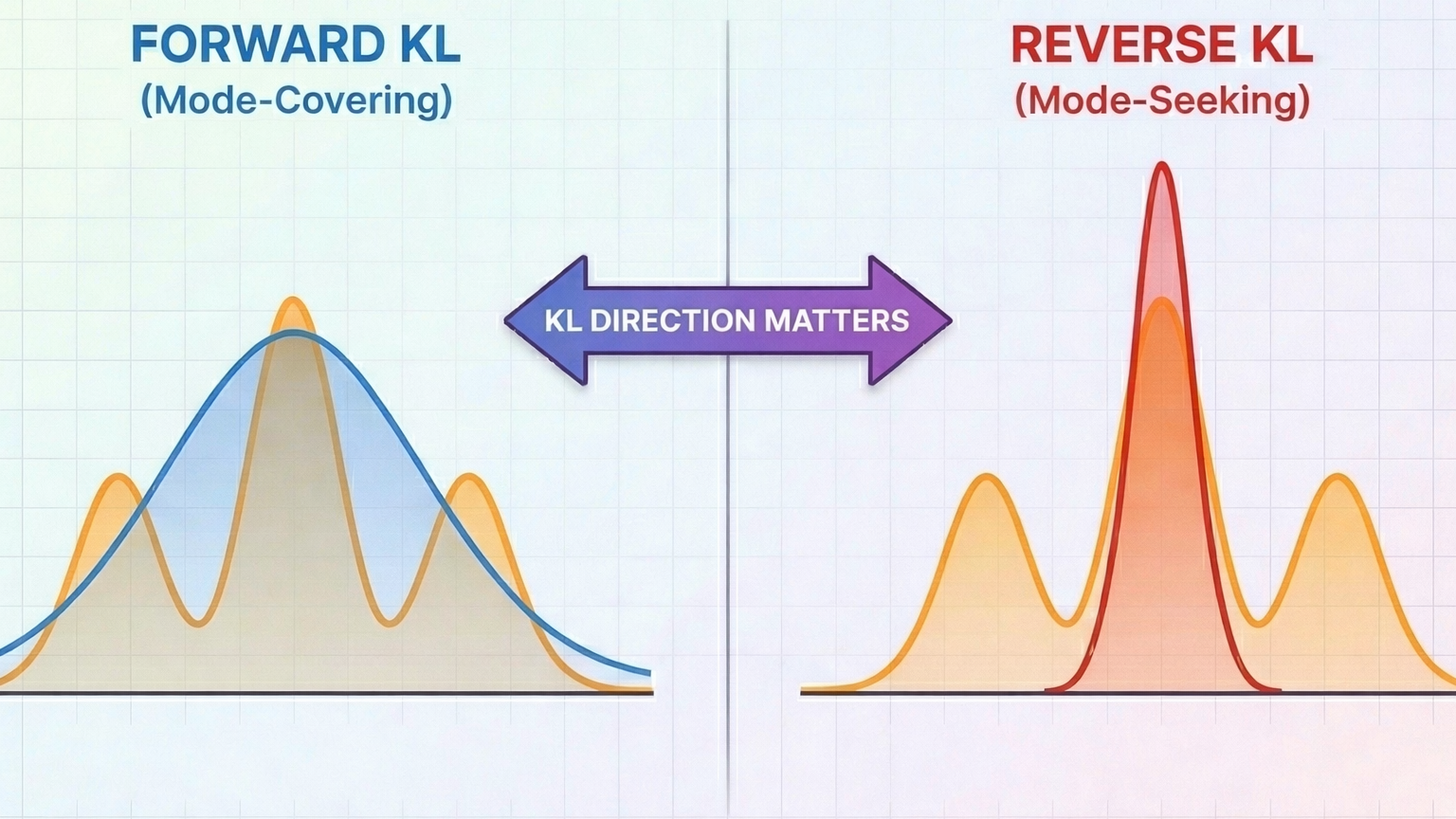
Why the direction of your KL divergence matters more than you think...

Strands vs AutoGen vs CrewAI — which one should you use?
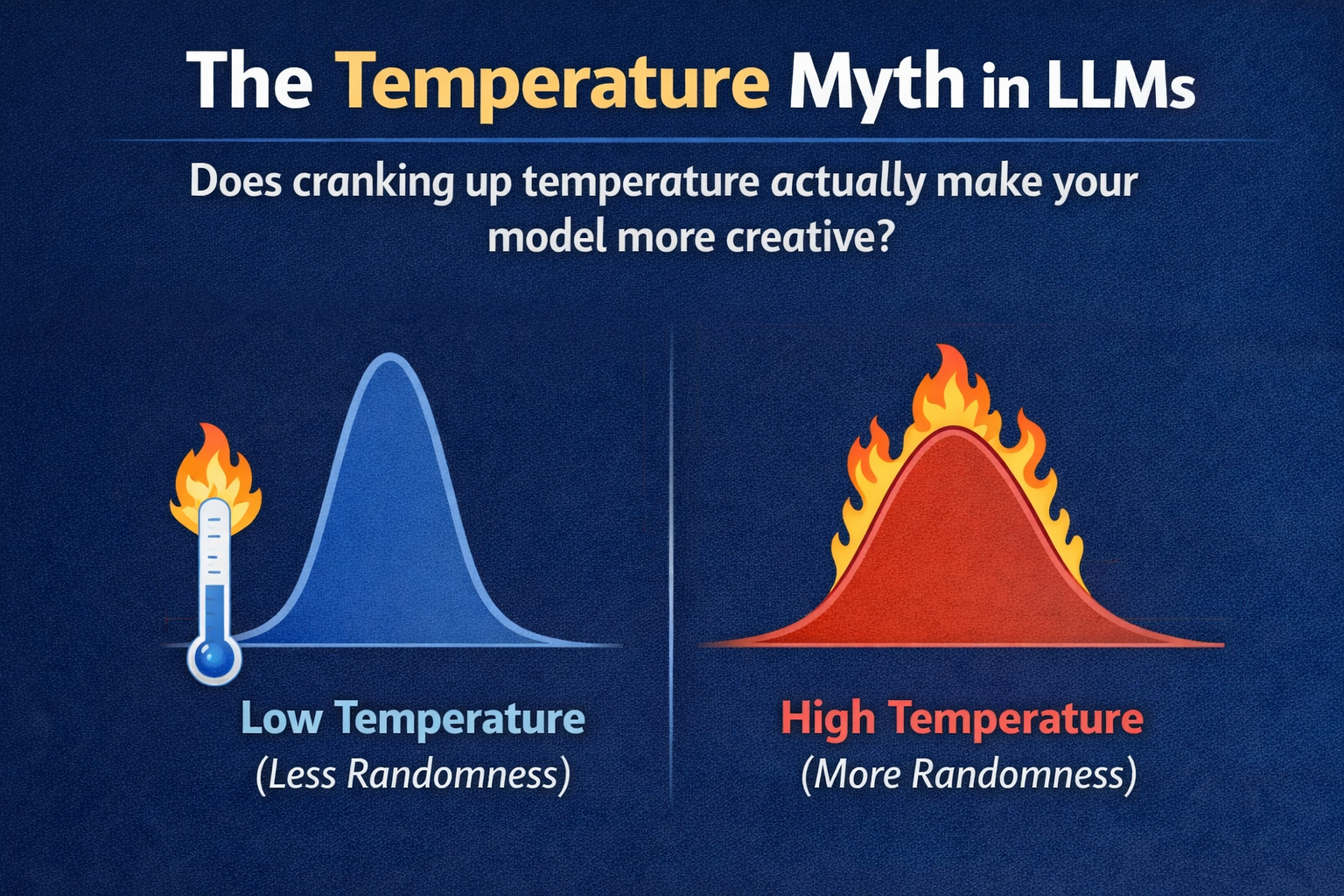
Does cranking up temperature actually make your model more creative?

Understanding the key optimization that makes LLM inference fast...

Speed up inference by guessing tokens — and being right most of the time...

The elegant math behind modern LLM position encoding...