Content Coming Soon
I'm currently working on this post. Check back soon for the full article with detailed explanations, visualizations, and code examples!
Why the direction of your KL divergence matters more than you think
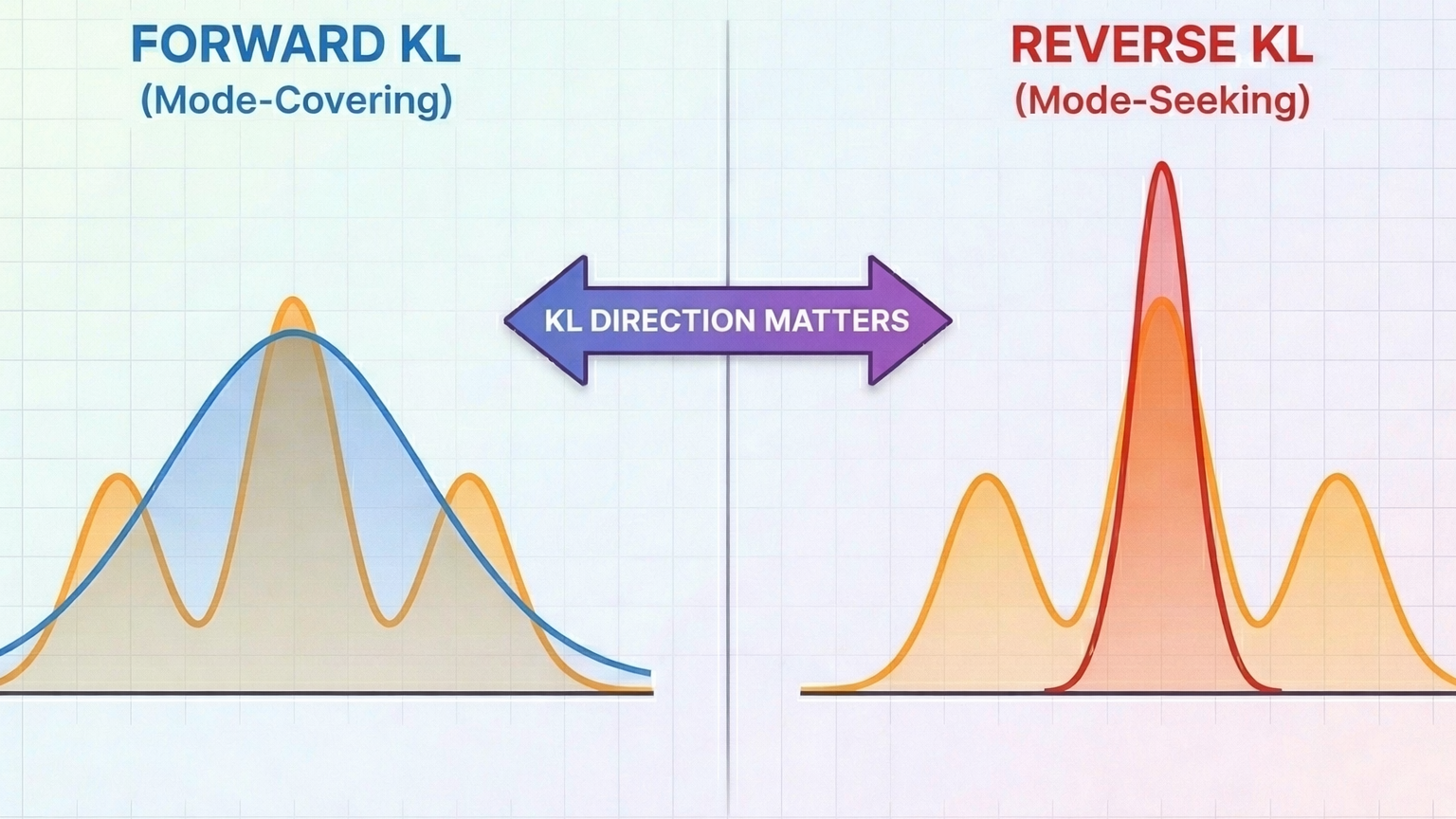
Forward KL (mode-covering) and reverse KL (mode-seeking) produce fundamentally different behaviors when training LLMs. Forward KL encourages the model to cover all modes of the target distribution, while reverse KL focuses on matching the highest probability regions. This choice has major implications for RLHF, distillation, and fine-tuning.
I'm currently working on this post. Check back soon for the full article with detailed explanations, visualizations, and code examples!